Last week, I went into detail on four key differences between Adobe and Google Analytics. This week, I’ll cover four more. This is far from an exhaustive list – but the purpose of these posts is not to cover all the differences between the two tools. There have been numerous articles over the years that go into great detail on many of these differences. Instead, my purpose here is to identify key things that analysts or organizations should be aware of should they decide to switch from one platform to another (specifically switching from Adobe to Google, which is a question I seem to get from one of my clients on a monthly basis). I’m not trying to talk anyone out of such a change, because I honestly feel like the tool is less important than the quality of the implementation and the team that owns it. But there are important differences between them, and far too often, I see companies decide to change to save money, or because they’re unhappy with their implementation of the tool (and not really with the tool itself).
Topic #5: Pathing
Another important difference between Adobe and Google is in path and flow analysis. Adobe Analytics allows you to enable any traffic variable to use pathing – in theory, up to 75 dimensions, and you can do path and next/previous flow on any of them. What’s more, with Analytics Workspace, you can also do flow analysis on any conversion variable – meaning that you can analyze the flow of just about anything.
Google’s Universal Analytics is far more limited. You can do flow analysis on both Pages and Events, but not any custom dimensions. It’s another case where Google’s simple UI gives it a perception advantage. But if you really understand how path and flow analysis work, Adobe’s ability to path on many more dimensions, and across multiple sessions/visits, can be hugely beneficial. However, this is an area Google has identified for improvement, and GA4 is bringing new capabilities that may help bring GA closer to par.

Topic #6: Traffic Sources/Marketing Channels
Both Adobe and Google Analytics offer robust reporting on how your users find your website, but there are subtle differences between them. Adobe offers the ability to define as many channels as you want, and define the rules for those channels you want to use. There are also pre-built rules you can use if you need. So you can accept Adobe’s built-in way of identifying social media traffic, but also make sure your paid social media links are correctly detected. You can also classify your marketing channel data into as many dimensions as you want.

Google also allows you as many channels as you want to use, but its tool is built around 5 key dimensions: source, medium, campaign, keyword, and content. These dimensions are typically populated using a series of query parameters prefixed with “utm_,” though they can also be populated manually. You can use any dimension to set up a series of channel groupings as well, similar to what Adobe offers.

For paid channels, both tools offer more or less the same features and capabilities; Adobe offers far more flexibility in configuring how non-paid channels should be tracked. For example, Adobe allows you to decide that certain channels should not overwrite a previously identified channel. But Google overwrites any old channel (except direct traffic) as soon as a new channel is identified – and, what’s more, immediately starts a new session when this happens (this is one of the quirkiest parts of GA, in my opinion).
Both tools allow you to report on first, last, and multi-touch attribution – though again, Adobe tends to offer more customizability, while Google’s reporting is easier to understand and navigate, GA4 offers some real improvements to make attribution reporting even easier. Google Analytics is also so ubiquitous that most agencies are immediately familiar with and ready to comply with a company’s traffic source reporting standards.
One final note about traffic sources is that Google’s integrations between Analytics and other Google marketing and advertising tools offer real benefits to any company – so much so that I even have clients that don’t want to move away from Adobe Analytics but still purchase GA360 just to leverage the advertising integrations.
Topic #7: Data Import / Classifications
One of the most useful features in Adobe Analytics is Classifications. This feature allows a company to categorize and classify the data captured in a report into additional attributes or metadata. For example, a company might capture the product ID at each step of the purchase process, and then upload a mapping of product IDs to names, categories, and brands. Each of those additional attributes becomes a “free” report in the interface. You don’t need to allocate an additional variable for it, but every attribute becomes its own report. This allows data to be aggregated or viewed in new ways. These classifications are also the only truly retroactive data in the tool – you can upload and overwrite classifications at any time, overwriting the data that was there previously. In addition, Adobe also has a powerful tool allowing you to not just upload your metadata, but also write matching rules (even using regular expressions) and have the classifications applied automatically, updating the classification tables each night.

Google Analytics has a similar feature, called Data Import. On the whole, Data Import is less robust than Classifications – for example, every attribute you want to enable as a new report in GA requires allocating one of your custom dimensions. However, Data Import has one important advantage over Classifications – the possibility to process the metadata in two different ways:
- Query Time Data Import: Using this approach, the metadata you upload gets mapped to the primary dimension (the product ID in my example above) when you run your report. This is identical to how Adobe handles its classification data.
- Processing Time Data Import: Using this approach, the metadata you upload gets mapped to the primary dimension at the time of data collection. This means that Google gives you the ability to report on your metadata either retroactively or non-retroactively.
This distinction may not be initially obvious, so here’s an example. Let’s say you capture a unique ID for your products in a GA custom dimension, and then you use data import to upload metadata for both brand name and category. The brand name is unlikely to change; a query time data import will work just fine. However, let’s say that you frequently move products between categories to find the one where they sell best. In this case, a query time data import may not be very useful – if you sold a pair of shoes in the “Shoes” category last month but are now selling it under “Basketball,” when you run a report over both months, that pair of shoes will look like it’s part of the Basketball category the entire time. But if you use a processing time data import, each purchase will be correctly attributed to the category in which it was actually sold.
Topic #8: Raw Data Integrations
A few years ago, I was hired by a client to advise them on whether they’d be better off sticking with what had become a very expensive Adobe Analytics integration or moving to Google Analytics 360. I found that, under normal circumstances, they would have been an ideal candidate to move to Google – the base contract would save them money, and their reporting requirements were fairly common and not reliant on Adobe features like merchandising that are difficult to replicate with Google.
What made the difference in my final recommendation to stick with Adobe was that they had a custom integration in place that moved data from Adobe’s raw data feeds into their own massive data warehouse. A team of data scientists relied heavily on integrations that were already built and working successfully, and these integrations would need to be completely rebuilt if they switched to Google. We estimated that the cost of such an effort would likely more than make up the difference in the size of their contracts (it should be noted that the most expensive part of their Adobe contract was Target, and they were not planning on abandoning that tool even if they abandoned Analytics).
This is not to say that Adobe’s data feeds are superior to Google’s BigQuery product; in fact, because BigQuery runs of Google’s ubiquitous cloud platform, it’s more familiar to most database developers and data scientists. The integration between Universal Analytics and BigQuery is built right into the 360 platform, and it’s well structured and easy to work with if you are familiar with SQL. Adobe’s data feeds are large, flat, and require at least cursory knowledge of the Adobe Analytics infrastructure to consume properly (long, comma-delimited lists of obscure event and variable names cause companies all sorts of problems). But this company had already invested in an integration that worked, and it seemed costly and risky to switch.
The key takeaway for this topic is that both Adobe and Google offer solid methods for accessing their raw data and pulling it into your own proprietary databases. A company can be successful integrating with either product – but there is a heavy switching cost for moving from one to the other.
Here’s a summary of the topics covered in this post:
| Feature | Google Analytics | Adobe |
| Pathing | Allows pathing and flow analysis only on pages and events, though GA4 will improve on this | Allows pathing and flow analysis on any dimension available in the tool, including across multiple visits |
| Traffic Sources/Marketing Channels | Primarily organized around use of “utm” query parameters and basic referring domain rules, though customization is possible
Strong integrations between Analytics and other Google marketing products |
Ability to define and customize channels in any way that you want, including for organic channels |
| Data Import/Classifications | Data can be categorized either at processing time or at query time (query time only available for 360 customers)
Each attribute/classification requires use of one of your custom dimensions | Data can only be categorized at query time
Unlimited attributes available without use of additional variables |
| Raw Data Integrations | Strong integration between GA and BigQuery
Uses SQL (a skillset possessed by most companies) | Data feeds are readily available and can be scheduled by anyone with admin access
Requires processing of a series of complex flat files |
In conclusion, Adobe and Google Analytics are the industry leaders in cloud-based digital analytics tools, and both offer a rich set of features that can allow any company to be successful. But there are important differences between them, and too often, companies that decide to switch tools are unprepared for what lies ahead. I hope these eight points have helped you better understand how the tools are different, and what a major undertaking it is to switch from one to the other. You can be successful, but that will depend more on how you plan, prepare, an execute on your implementation of whichever tool you choose. If you’re in a position where you’re considering switching analytics tools – or have already decided to switch but are unsure of how to do it successfully, please reach out to us and we’ll help you get through it.
Photo credits: trustypics is licensed under CC BY-NC 2.0

















































































































































 If you are a veteran Adobe Analytics (or Omniture SiteCatalyst) user, for years the term attribution was defined by whether an eVar was First Touch (Original Value) or Last Touch (Most Recent). eVar attribution was setup in the administration console and each eVar had a setting (and don’t bring up Linear because that is a waste!). If you wanted to see both First and Last Touch campaign code performance, you needed to make two separate eVars that each had different attribution settings. If you wanted to see “Middle Touch” attribution in Adobe Analytics, you were pretty much out of luck unless you used a “hack” JavaScript plug-in called
If you are a veteran Adobe Analytics (or Omniture SiteCatalyst) user, for years the term attribution was defined by whether an eVar was First Touch (Original Value) or Last Touch (Most Recent). eVar attribution was setup in the administration console and each eVar had a setting (and don’t bring up Linear because that is a waste!). If you wanted to see both First and Last Touch campaign code performance, you needed to make two separate eVars that each had different attribution settings. If you wanted to see “Middle Touch” attribution in Adobe Analytics, you were pretty much out of luck unless you used a “hack” JavaScript plug-in called  However, this has changed in recent releases of the Adobe Analytics product. Now you can apply a bunch of pre-set attribution models including J Curve, U Curve, Time Decay, etc… and you can also create your own custom attribution model that assigns some credit to first, some to last and the rest divided among the middle values. These different attribution models can be built into Calculated Metrics or applied on the fly in metric columns in Analysis Workspace (not available for all Adobe Analytics packages). This stuff is really cool! To learn more about this,
However, this has changed in recent releases of the Adobe Analytics product. Now you can apply a bunch of pre-set attribution models including J Curve, U Curve, Time Decay, etc… and you can also create your own custom attribution model that assigns some credit to first, some to last and the rest divided among the middle values. These different attribution models can be built into Calculated Metrics or applied on the fly in metric columns in Analysis Workspace (not available for all Adobe Analytics packages). This stuff is really cool! To learn more about this, 




















 Back in 2015, the Analytics Demystified team decided to put on a different type of analytics conference we called ACCELERATE. The idea was that we as partners and a few select other industry folks would share as much information as we could in the shortest amount of time possible. We chose a 10 tips in 20 minutes format to force us and our other presenters to only share the “greatest hits” instead of the typical (often boring) 50 minute presentation with only a few minutes worth of good information. The reception of these events (held in San Francisco, Boston, Chicago, Atlanta and Columbus) was amazing. Other than some folks feeling a bit overwhelmed with the sheer amount of information, people loved the concept. We also coupled this one day event with some detailed training classes that attendees could optionally attend. The best part was that our ACCELERATE conference was dramatically less expensive than other industry conferences.
Back in 2015, the Analytics Demystified team decided to put on a different type of analytics conference we called ACCELERATE. The idea was that we as partners and a few select other industry folks would share as much information as we could in the shortest amount of time possible. We chose a 10 tips in 20 minutes format to force us and our other presenters to only share the “greatest hits” instead of the typical (often boring) 50 minute presentation with only a few minutes worth of good information. The reception of these events (held in San Francisco, Boston, Chicago, Atlanta and Columbus) was amazing. Other than some folks feeling a bit overwhelmed with the sheer amount of information, people loved the concept. We also coupled this one day event with some detailed training classes that attendees could optionally attend. The best part was that our ACCELERATE conference was dramatically less expensive than other industry conferences.


















































































































































































 Opening day if you will. The general session followed up by many sessions and labs. This sounds silly but I always come early to have breakfast at the conference. I have had many a great conversation and met so many interesting people by simply joining them at the table. I do this for all the lunches each day as well. We are all pretty much there for similar reasons and have similar interests so it is nice to geek out a bit and network as well.
Opening day if you will. The general session followed up by many sessions and labs. This sounds silly but I always come early to have breakfast at the conference. I have had many a great conversation and met so many interesting people by simply joining them at the table. I do this for all the lunches each day as well. We are all pretty much there for similar reasons and have similar interests so it is nice to geek out a bit and network as well.


































































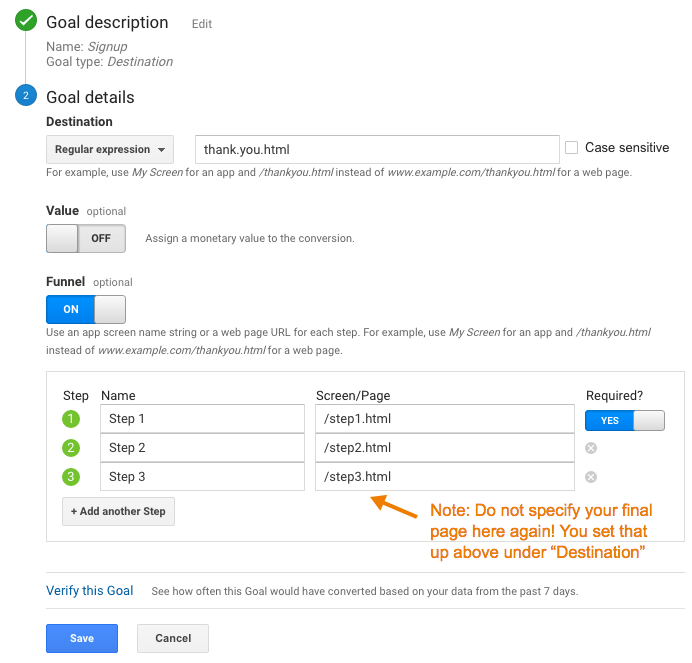
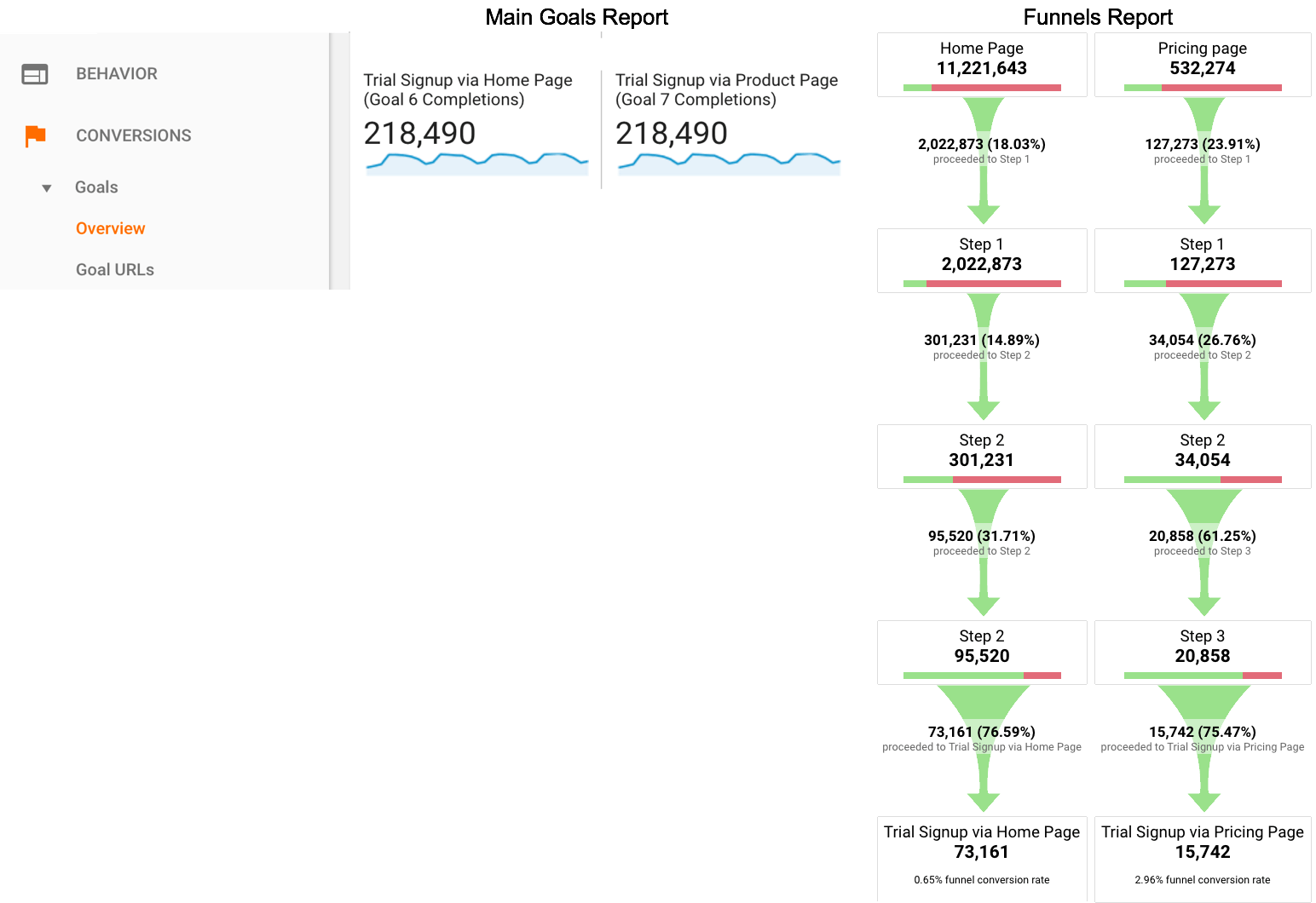
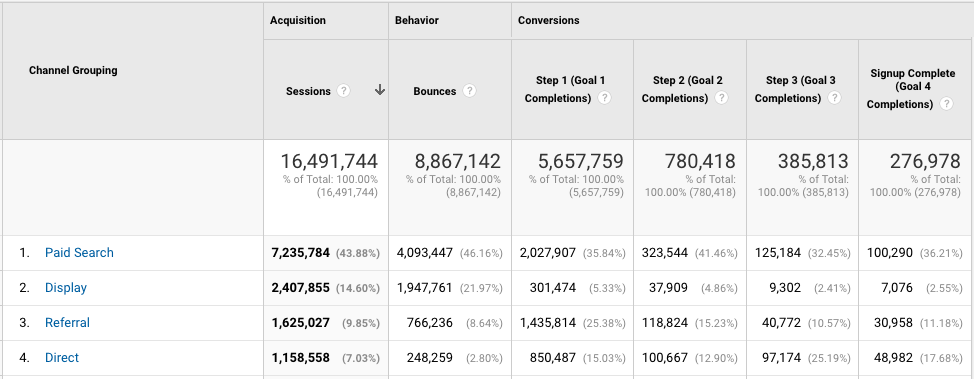

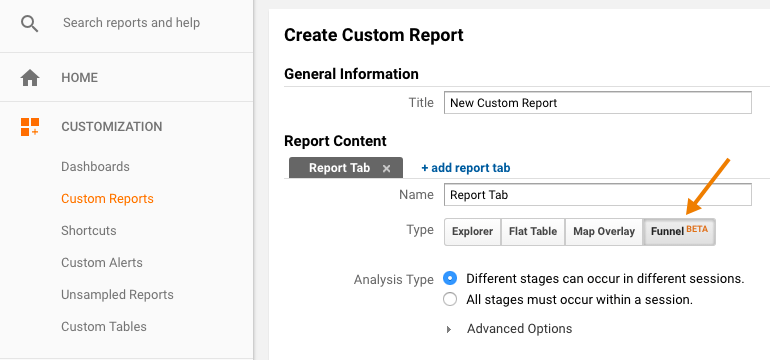




 To illustrate, let’s think about how we view traffic by channel:
To illustrate, let’s think about how we view traffic by channel: Several statistically-savvy analysts I have chatted with have said something along the lines of, “You know, really, to ‘get’ statistics, you have to start with probability theory.” One published illustration of this stance can be found in
Several statistically-savvy analysts I have chatted with have said something along the lines of, “You know, really, to ‘get’ statistics, you have to start with probability theory.” One published illustration of this stance can be found in 





















































































{kind=link}
{kind=link}
{kind=link}
{kind=link}