Recently, I gave a presentation in which I posited that tracking every single hyperlink on a web page is not what digital analytics is all about. I argued that looking at every link on a page can create a lot of noise and distract from the big picture KPI’s that need to be analyzed. This led to a debate about the pros and cons of tracking every link, so I thought I would share some of my thoughts here and see if anyone had opinions on the topic.
Why Track Everything?
I have some clients who endeavor to track every link on their site. Most of these pass the hit level data to Hadoop or something similar and feel that the more data the better, since data storage is cheaper every day. For those using Adobe Analytics, these links are usually captured in an sProp and done through a query string parameter on the following page or a Custom Link. In Adobe Analytics, the sheer number of these links often hits the monthly unique value limit (low traffic), so the data is somewhat less useful in the browser-based reporting interface, but is fine in DataWarehouse and when data is fed to back-end databases.
But if you ask yourself what is the business goal of tracking every link on a page, here are the rationalizations I have heard:
- We want to know how each link impacts conversion/success;
- We want to see which links we can remove from the page;
- If multiple links to the same page exist, we want to know which one is used more often;
- We just want to track everything in case we need it later.
Let’s address these one at a time. For the first item, knowing how each link contributes to success is possible, but since many links will be used prior to conversion, several should get credit for success. In Adobe Analytics, you can assign this contribution using the Participation feature, but this becomes problematic if you have too many links tracked and exceed the monthly unique limit. This forces you to resort to DataWarehouse or other systems, which puts analysis out of the hands of most of your business users but is still possible by a centralized analytics team that is a bit more advanced. Instead of doing this, I would propose that instead of tracking every link, you pick specific areas of the website that you care about and track those links in an sProp (or an eVar). For example, if you have an area on your website that is a loan calculator, you can track all of the discrete links there in a custom variable. You can then turn on Participation and Pathing for that variable and get a good sense of what is and is not being used and not exceed any unique variable limits. I would also argue that once you learn what you have to learn, you can re-use the same variable for a different area of your website in the same way (i.e. loan application form pages). Hence, instead of tracking every link on the website, you are more prescriptive on what you are attempting to learn and can do so with greater accuracy. If you need to track several areas of the site concurrently, you can always use multiple variables.
For the second question – seeing which links can be removed from the page – I have found that very few analyses on links have actually resulted in links being dropped from pages. In general, most people look to see how often Page A leads to Page B or Page C and by the time they get to Page Z, the referral traffic is very low. If you truly want to remove extraneous links, you could start by finding the pages that people rarely go to from Page A and then remove the links to those pages on Page A. Doing this doesn’t require doing granular link tracking.
Next, there is the age-old question of which link, of multiple going to the same place, people use. I am not quite sure why people are so fascinated with these types of questions, but they are! In most cases, I find that even after conducting the analysis, people are loathed to remove the duplicative links for fear of negatively impacting conversion (just in case). Therefore, for cases like this, I would suggest using A/B testing to try out pages that have duplicate links removed. Testing can allow you to see what happens when secondary or tertiary links are removed, but for a subset of your audience. If the removal doesn’t negatively impact the site, then you can push it site-wide after the test is complete.
Lastly, there is the school of thought that believe they should track everything just in case it is ever needed. This has become easier over the years as data storage prices have fallen. I have seen many debates rage about whether time should be spent pre-identifying business requirements and tracking specific items desired by stakeholders or just tag everything and assume you may need it later. Personally, I prefer the former, but I don’t disparage those who believe in the latter. If your organization is super-advanced at data collection, has adequate database expertise and an easy way to analyze massive amounts of data, tracking everything may be the right choice for you. However, in my experience, most analytics teams struggle to do a great job with a handful of business questions asked by stakeholders and the addition of reams of link-level data could easily overwhelm them. For every new thing that you track, you need to provide QA, analysis and so on, so I would advise you to focus on the biggest questions your stakeholders have. If you ever get to the point where you have satisfied those and have processes in place to do so in an efficient manner, then you may want to try out “tracking everything” to see how much incremental value that brings. But I do not advise doing it the other way around.
Focus on KPI’s
The other complaint that I have about tracking every link is that it takes time away from your KPI’s. Most analytics teams are busy and strapped for resources. Therefore, focusing time on the most important metrics and analyses is critical. I have seen many companies get bogged down in detailed link tracking that results in nominal potential ROI increases (is the juice worth the squeeze?). Just outlining all of the links to be tracked can take time away from analysts doing analysis, not to mention the time spent analyzing all of the data. In addition, doing granular link tracking can sometimes require a lot of tagging and quality assurance, which takes developers away from other efforts. Developers’ time is usually at a premium, so you need to make the most of it when you have it.
Consider Other Tools
If you are truly interested in tracking every link, I would suggest that you consider some other analytics tools that may be better suited for this work (vs. Adobe Analytics). One set of tools to consider are heat map and session replay tools. I often find that when analytics customers want to track every link on the site, many times, they really want to understand how people are using the different areas of the site and are not aware that there are better tools suited to this function. While heat map tools are not perfect (after many years, even the Adobe Click Map tool takes extra work to make it functional), they can provide some good insights into which parts of pages visitors are viewing/clicking and answer some of the questions described above. I have even seen some clients use detailed link data in Adobe Analytics to create a “heat map” view of a page manually (usually in PowerPoint), which seems like a colossal waste of time to me! I suggest checking out tools like Crazy Egg and others in the heat mapping area.
Personally, I am a bigger fan of session replay tools like Decibel Insight (full disclosure: I am on the advisory board for Decibel), because these tools allow you to see people using your website. I have found that watching someone use an area of your website can often time be easier that analyzing rows and rows of link click data. Unfortunately, just as in engineering or construction, sometimes using the wrong tool can lead you down a path that is way more complicated than you need versus simply selecting the right tool for the job in the beginning. Most of these tools can also show you heat maps, which is nice as it reduces the number of disparate tools you need to work with and pay for.
Lastly, if tracking every link is absolutely essential, I would check out tools like Heap or Mixpanel, which is pre-built for this type of tracking. But in general, when you are in meetings where link-level tracking is discussed, keep these tools in mind before doing a knee-jerk reaction to use your traditional analytics tool.
Final Thoughts
There you have some of my thoughts on the topic of tracking every link on your site. I know that there will be some folks who insist that it is critical to track all links. On that, I may have to agree to disagree, but I would love to hear arguments in favor of that approach as I certainly don’t profess to know everything! I have just found that doing granular link tracking produces minimal insights, can create a lot of extra work, can detract time from core KPI’s and sometimes can be more effective using different toolsets. What say you?























































































 The Measure Slack was created and is spearheaded by
The Measure Slack was created and is spearheaded by 





























































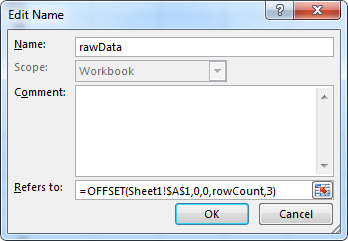

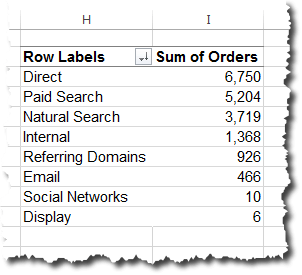
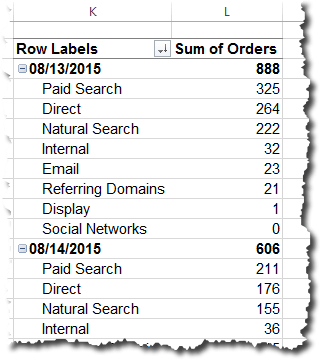
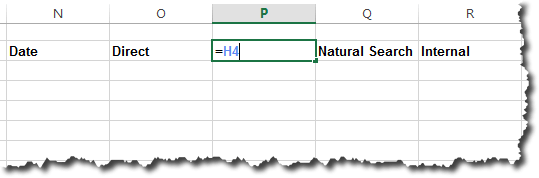


















 Then we simply configure the plug-in here:
Then we simply configure the plug-in here: The area surrounded by a red box is where you select the previously created HTML offer with your plug-in code. You also have the option to specify when the code gets fired. Typically you want it to only fire when a visitor becomes a member of a test or when test content (T&T offers) are being displayed and to do so, simply select, Display mbox requests only. If you wanted to, you can have your code fire on all mbox requests as that can be need sometimes. Additionally, you can limit the code firings to a particular mbox or even by certain date periods.
The area surrounded by a red box is where you select the previously created HTML offer with your plug-in code. You also have the option to specify when the code gets fired. Typically you want it to only fire when a visitor becomes a member of a test or when test content (T&T offers) are being displayed and to do so, simply select, Display mbox requests only. If you wanted to, you can have your code fire on all mbox requests as that can be need sometimes. Additionally, you can limit the code firings to a particular mbox or even by certain date periods. Now that we understand that, lets see what the integration gets you:
Now that we understand that, lets see what the integration gets you: What we have here is a report of a specific Google Analytics Event Category, in this case the Test&Target Event. Most of my clients have many Event Categories so it’s important to classify Test&Target as a separate Event and this plug-in code does that for you.
What we have here is a report of a specific Google Analytics Event Category, in this case the Test&Target Event. Most of my clients have many Event Categories so it’s important to classify Test&Target as a separate Event and this plug-in code does that for you. Here we can look at how a unique test and its experiences impacted given success events captured in Google Analytics. Typically, most organizations include their key success events for analysis in T&T but this integration is helpful if you want to look at success events not included in your T&T account or if you want to see how your test experiences impacted engagement metrics like time on site, page views, etc….
Here we can look at how a unique test and its experiences impacted given success events captured in Google Analytics. Typically, most organizations include their key success events for analysis in T&T but this integration is helpful if you want to look at success events not included in your T&T account or if you want to see how your test experiences impacted engagement metrics like time on site, page views, etc….{kind=link}
{kind=link}