Those of you who follow my blog have come to know that when I learn a product (like Adobe SiteCatalyst), I really get to know it and evangelize it. Back in the 90’s I learned the Lotus Notes enterprise collaboration software and soon became one of the most proficient Lotus Notes developers in the world, building most of Arthur Andersen’s global internal Lotus Notes apps. In the 2000’s, I came across Omniture SiteCatalyst, and after a while had published hundreds of blog posts on Omniture’s (Adobe’s) website and my own and eventually a book! One of my favorite pastimes is finding creative ways to apply a technology to solve everyday problems or to make life easier.
That being said, this post has to do with my new favorite technology – Slack. Admittedly, this post has very little to do with web analytics or Adobe Analytics, so if that is what you are interested in, you can stop reading now. But I suggest that you continue reading, as it may give you a heads-up on one of the most interesting technologies I have seen in a while, and maybe you will get as addicted to it as I am…
What is Slack?

If you have not yet heard of Slack – you will soon. It is one of the hottest technologies out there right now (started almost by accident), and has the potential to change the way business gets done. Slack is a tool that allows teams to collaborate around pre-defined topics (channels) and private groups. It also provides direct messaging between team members and integrations with other technologies. I think of it as a team message board, instant messaging, a file repository and private group discussions all in one place. That sounds deceptively simple (like its interface), but it is extremely powerful. Most people work with a finite number of folks on a daily basis. Those interactions take place in face-to-face meetings, e-mails, file sharing on dropbox, phone calls and often times instant message interactions. Unfortunately, this means that you have to constantly jump between your phone, your e-mail client, your IM client, your dropbox account, etc… Sometimes you may feel like you spend a good chunk of your day just looking for stuff instead of doing real work! The beauty of Slack is that you can push almost all of these interactions and content into one centralized tool and that tool can be accessed from a webpage, a [great] mobile app or a desktop app (I use the Mac client). In addition the integrations Slack provides with other tools like Dropbox, WordPress, Twitter ZenDesk, etc… allow you to push even more things into the Slack interface so you have even fewer places to go and find stuff.
At our consultancy, we have seen a massive adoption of Slack and our use of e-mail has decreased by at least 75%. If you have kids like mine, who never bother to open an e-mail, but live for text messages, you can imagine that this trend will only continue as the younger generation enters the workforce. The business world moves too fast these days and I think the millennials will flock to tools like Slack in the future. So…in this post, I am going to do what I always do – share cool ways to use technology and share what I have done with it. Please bear with me as I put web analytics on hold for one post!
Channels
The first way our firm uses Slack is by taking advantage of the “channel” feature. Channels are like bulletin boards with a pre-defined topic. For example, some people at our firm are interested in Adobe Analytics products, while others are interested in Google Analytics products (or both). By creating a channel for each of these, anyone can post an article, share a file, ask a question or share something they learned in the appropriate channel. Everyone within the team has the choice as to whether they want to “join” the channel. If you join the channel, you can see all of the stuff posted there and set your notifications accordingly (determine if you want desktop or mobile notifications- more on this later). You can leave a channel at any time and re-join at any time, and there are no limits on the number of channels you can create (as far as I know).
As an example, here you can see some questions posed within our Adobe channel and how easy it was for our team members to get answers that might have otherwise sat buried in e-mail:

Keep in mind that in addition to text replies, users could have inserted images, files, links or videos into the above thread. Also remember that some of these replies could have come from the mobile app while folks are on the road.
Private Groups
If you want to have a private channel, with just a few folks, you can create a Private Group. Private Groups are like group instant message threads, but can also contain files, images, etc. We use Private Groups for client projects in which multiple team members are involved. In the Private Group, any questions or updates related to THAT client are shared with only those team members who are involved in the project (instead of everyone publicly). Just the other day, we had a client encounter a minor emergency, and immediately our team began discussing options on Slack, came to a resolution and implemented some patch code to fix the client issue. In the past, it would have taken us hours to schedule a meeting, review the issue and figure out a solution, but with Slack the entire process was done in under ten minutes and the client was blown away!
Another great use for Private Groups is tele-conference calls. We use this as a “backchannel” when on client calls to chat with each other during calls to make sure we are all on the same page with our responses.
File Sharing
Many of us spend our lives making and editing files. Whether they be spreadsheets, presentations, etc… To store these files, many companies use Dropbox or something similar. As you would expect, Slack has a tight integration with these tools. Since we use Dropbox, I’ll use that as an example. I have connected my Dropbox account to Slack so when I choose to import a file, I see Dropbox as one of the options:

From there, I find the file I am looking for…

…and then I add it to Slack:

This process only takes a few seconds, but the cool part is that the entire document I have uploaded will be indexed and be searchable from now on:

Another thing that has frustrated me in the past related to file sharing, is not knowing when my co-workers are creating great new documents. Unless you are continuously reviewing Dropbox notifications (which are way to numerous), a lot of this activity can slip through the cracks. Luckily, there is another cool feature in Slack that can come to the rescue! This feature is found within the Notifications area. Within this area there is a “Highlight Words” box that allows you to list out specific phrases that you want to be alerted about. In this example, I have listed three specific words for which I want Slack to notify me about whenever they occur within a document, channel discussion or private group that I have access to see:

As you can see below, my designated words are highlighted and I will see an unread count for any items that match my criteria:

In addition to highlighting keywords, you can also use one of my favorites tools – IFTTT (or Zapier) to be alerted when a new file has hit your file tool of choice. Hopefully you are already familiar with these great tools that allow you to connect different technologies. But Slack + IFTTT/Zapier = 🙂 in my opinion! Let’s look at one practical example. Imagine that I want to know anytime one of my partners has created a new proposal and added it to our shared dropbox folder. Since they may not have remembered that they should always include my services in their proposal, I like to gently remind them! To do this, I can have IFTTT/Zapier monitor our “Proposal” dropbox folder for new files and post a link to new proposals to a Private Group or Public Channel so we are all aware of each other’s proposals. For example, let’s say that I see a new proposal come in from one of my partners for XYZ Company and I know the CIO there. Having visibility into this activity allows me to help and takes no extra work for my partner. Here is an example of the Zapier recipe I might use:

This recipe will automatically post any new files in the proposals dropbox folder to the “proposals” channel, which any of my co-workers can follow if they choose:

As you can see, there are tons of ways to share files and be alerted when your co-workers are adding files that might be of interest to you and most of them integrate into Slack automatically.
Slack – Twitter Integration
If you are into Twitter, you probably spend time tweeting, following people or monitoring hashtags. To do this, you may use the Twitter site or App (old Tweetdeck app). For me, there are only a few things I really care about when it comes to Twitter:
- Is someone talking about me or re-tweeting my stuff?
- Are my business partners tweeting?
- Is there anything going on in the hashtags I care about (though these are becoming SPAM so I care less about this these days!)?
The good news is that I can now monitor all of this in Slack, again using IFTTT (or Zapier). So let’s see how this integration would be setup. First, let’s get all of my Twitter mentions into Slack. To do this, I would simply create a recipe in IFTTT that connects Twitter to Slack using the following:

In this case, I have decided to post my Twitter mentions to a private channel called “adam-twitter-mentions” that only I see. I could have alternatively posted them to my personal “Slackbot” area (which is like your own personal notepad within Slack), but I didn’t want to clutter that with Twitter mentions (since I have some cool uses for that coming later). Once this rule is active, any time I am mentioned on Twitter, a copy of the Tweet will be automatically imported into my private Slack group and I will see a new “unread” item as seen here:

Next, I want to know if any of my co-workers are tweeting, since I may want to be a good partner and re-tweet their stuff to my personal network. To do this, I create a different IFTTT recipe that looks for their Twitter handles. I am lucky to work with a small group of folks, but you can add as many of your co-workers as you want and also include your company’s Twitter account as well:

This recipe will run every fifteen minutes or so and push tweets from these accounts to a public “tweets-demystified” channel. My co-workers then have the option to subscribe to this channel or not:

Finally, if I want to follow a specific Twitter hashtag, I can create a recipe for that. As an example, if I want to follow the #Measure hashtag (used by the web analytics industry), I can push in all of those tweets into Slack using this recipe:

In this example, I am pushing #Measure tweets to my personal “Slackbot” just for illustrative purposes, but in reality, I would probably create a private group or channel for this given that a LOT of data will end up here:

As you can see, I now have the things I care the most about in Twitter in the same tool that I am using to collaborate with my co-workers, clients and conduct instant messages. This helps me by reducing the number of tools I have to interact with, but there are other reasons to do this as well. First, The tweets in Slack can be commented on by my partners, which can lead to fun and interesting discussions. But my favorite reason for doing this is that everything imported into Slack is 100% searchable. In this case, this means that I can search amongst all of my tweets and my co-workers’ tweets from today on, and don’t have to go to different tools to do it. Let’s say I am doing some research on “Visitor Engagement” for a client. I can now go to Slack and search for “Visitor Engagement,” and know that I will find any discussions, files and tweets that mention “Visitor Engagement” within my company (and if I include the hashtag tweets, I can also see if anyone else in the world has written about it!). That is extremely powerful!
Slack – Blog Integration
Another thing I may want to be aware of, is when my co-workers release new blog posts. Our firm uses both WordPress and Tumblr, which can both be integrated with Slack. This integration is pretty straight-forward in that it simply posts a link to Slack whenever each of us posts something new. To do this, we created a blog channel and I created an IFTTT rule to push new posts into the channel using this recipe:

This will result in the following in Slack:

Slack – Pocket Integration
While on the subject of sharing blog posts, another one of my favorite Slack integrations uses Pocket to move blogs and articles into Slack. If you are not familiar with Pocket, it is a handy tool that allows you to save web pages that you want to read later and apply tags to them. For example, if I see an article on Twitter that I like and want to read later or share with a co-worker, I can save it to my Pocket list and then retrieve it in the future through the Pocket mobile app or website. But using Pocket with Slack takes this to a new level. In IFTTT, I have created a series of recipes that map Pocket tags to channels in our Slack implementation. For example, if I want to share a blog post I liked with my co-workers, all I need to do is save it to Pocket and tag it with the tag “blog” and within fifteen minutes, a link to it will be posted in the previously shown “industry-news-blogs” channel. Here is what the recipe looks like:

Once again, my partners can comment on it and the article text is fully searchable from now on. In my case, I have set-up several of these recipes, such that if I find a good article about Adobe technology, it will be posted to our “Adobe” channel and likewise for Google.
Slack – Email Integration
Another type of content that I may want to push into Slack is e-mail. While Slack does reduce e-mail usage, e-mail will probably never go away. The Slack pricing page states that more e-mail to Slack functionality is coming soon, but in the meantime, I found another way to use IFTTT to send specific e-mails into Slack. Before I show how to do this, let’s consider why sending e-mails into Slack could be worthwhile. In general, I wouldn’t want to clutter my Slack implementation with ALL of my e-mail, but there are times when an important e-mail comes through that may be useful in the future. Perhaps it is a key project status update or approval from your client or boss that you want to save in case the s#%t hits the fan one day! Another reason might be to take advantage of the full-text searching capabilities of Slack so that future searches will include key e-mail messages.
Regardless of your reason, here is an example of how I push e-mails from my work Gmail account into Slack. First, I create a Gmail label that I will use to tell IFTTT which e-mails should be sent. In my case, I simply made a label named “Slack” (keep in mind it is case-sensitive) using normal Gmail label functionality. Next, I created the following recipe in IFTTT:

Once this is active, all I need to do is apply the label of “Slack” to any e-mail and it will be sent to Slack:

In this case, I am pushing e-mails to my personal “Slackbot” since I don’t plan to do this very often and it is an easy, private place to keep these messages. Of course, I could have just as easily pushed these e-mails into a private group, but for now Slackbot will meet my needs.
Slack – Task Management Integration
If your company uses a task/work management tool like Asana, Wunderlist, etc., you can push new task starts and completions into project channels. This allows all team members to see progress being made and to ask questions about tasks via the reply feature in Slack:

Guest & Restrictred Access
If you work in a business where you need to share discussions and files with people outside of your organization, you use the paid version of Slack to create special accounts that allow you to grant limited Slack access to external users:

We use this feature to add clients to private groups for projects. This gives is a direct line to our clients and an easy way for them to post project questions and files. Instead of sending an e-mail and copying tons of people, clients can post a query to the Slack group and know that one of the team members will get back to them in short order. This feature also helps us get around limitations associated with sending large files over e-mail or the need to send secure messages via Dropbox.
Notifications
Through Slack’s highly customizable notifications area, you can determine how often you want Slack to bug you about activity in each of your channels and groups. For example, you can see below, that while I am working during the day, I have notifications turned off on my desktop for many of my channels. This means that my Mac won’t pop-up stuff and distract me from my work, but I can still tab over to Slack anytime I want and see how much new activity is there. But if something is posted in the “all-demystified” channel, I will get a mobile alert, since that tends to be more important stuff (per our internal policy). I often get many questions in the “Adobe” channel, so if my name is mentioned there, I will also get alerted on my mobile device:

Summary
As you can see, I have had a lot of fun using Slack at our company and pushing all sorts of content into it so it becomes our primary focal point for communication. Unfortunately, due to client restrictions, I can’t show some of the coolest ways we have used the tool, but my hope is that this post helps you see how a seemingly simple tool can do many powerful things when thought of as a central repository for knowledge for yourself and your company. Since Slack is a young company, I am sure that more features and integrations will be forthcoming, but I highly recommend that you check it out (this link includes a $100 credit in case you ever want the paid version) by finding a group of people at your company who need to collaborate on a regular basis or on a specific project. The best part is that you can start with Slack for free and then graduate to the paid version once you are as addicted as I am!
If you want to stay up to date on the latest Slack features and enhancements, subscribe to this IFTTT recipe…

…and this recipe which shares periodic tips:

Internally, I have created a public channel for both of these items so our team can learn more about Slack
Finally, if you are a Slack user and have found other super-cool things you can do with it, please share those here…Thanks!


































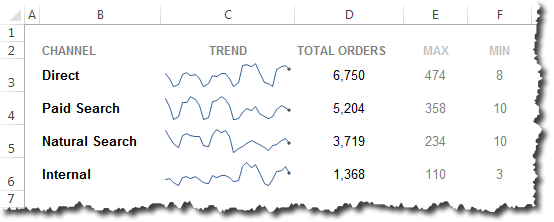
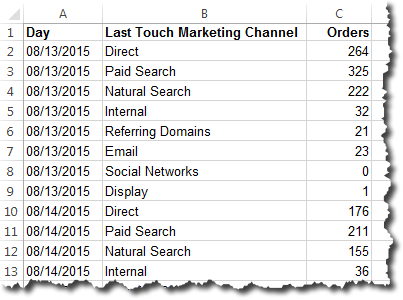
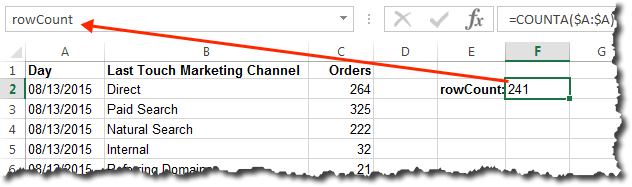
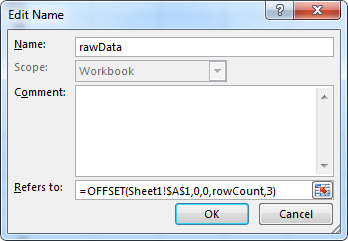
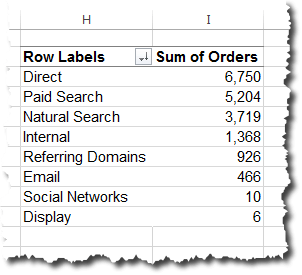
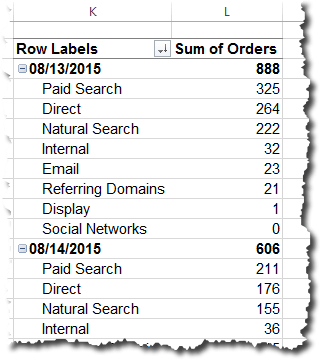
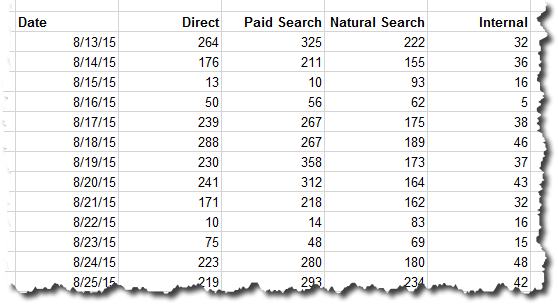
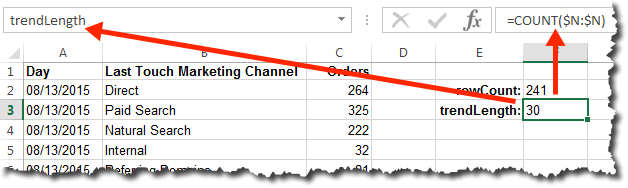
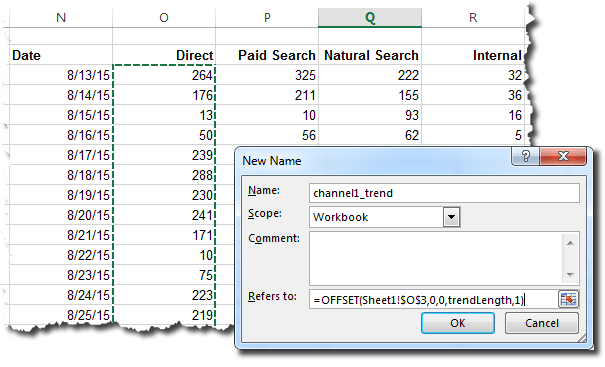
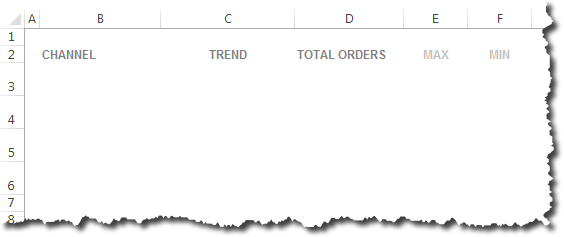
 To illustrate, let’s think about how we view traffic by channel:
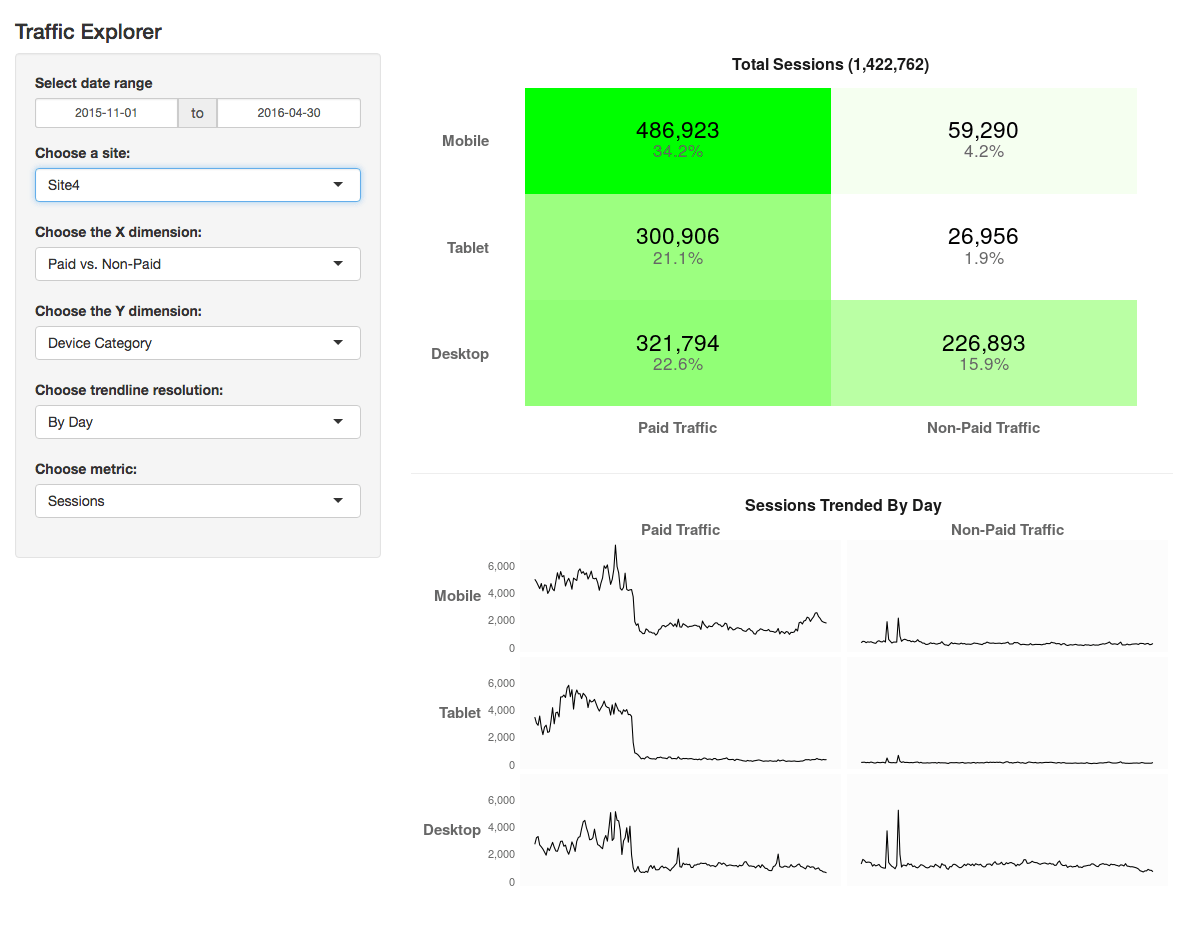
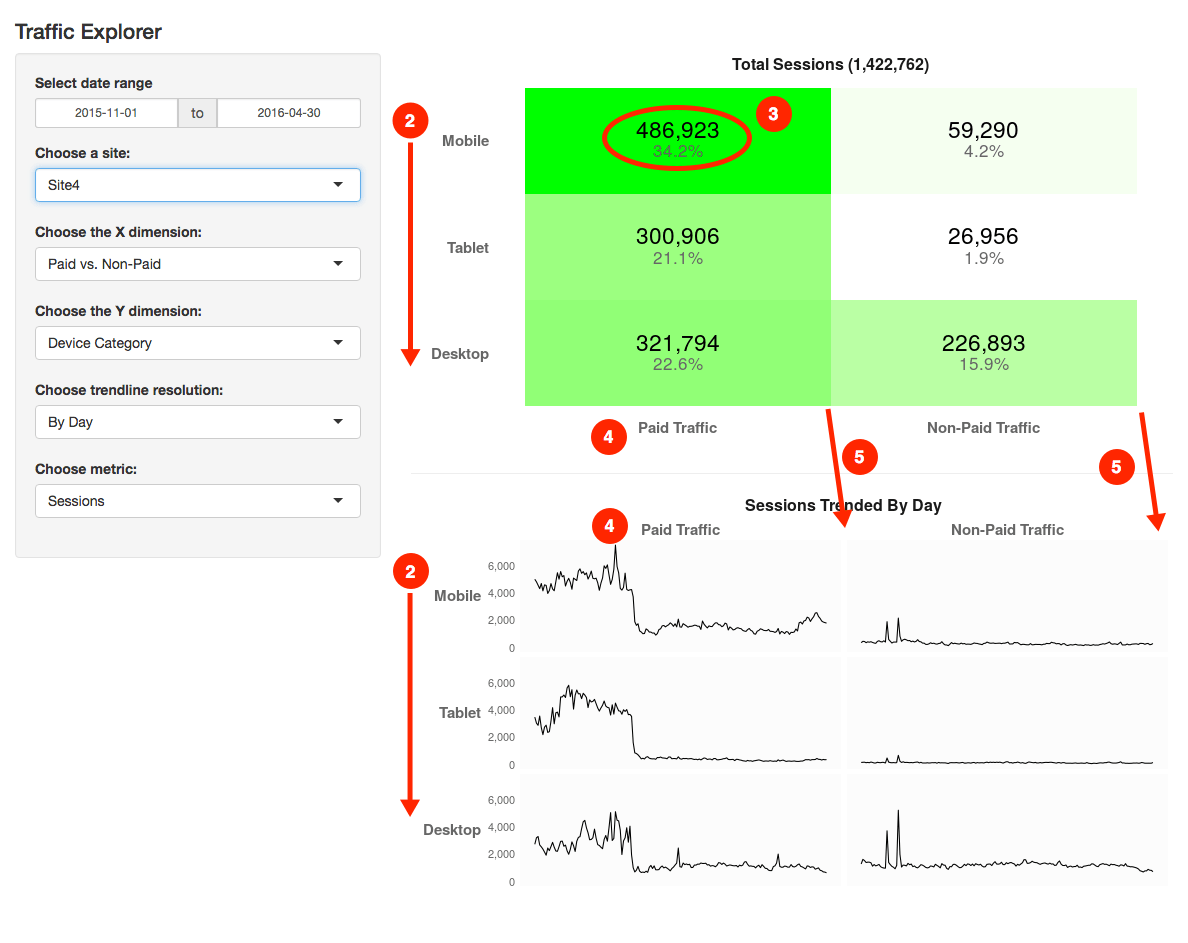
To illustrate, let’s think about how we view traffic by channel: Several statistically-savvy analysts I have chatted with have said something along the lines of, “You know, really, to ‘get’ statistics, you have to start with probability theory.” One published illustration of this stance can be found in
Several statistically-savvy analysts I have chatted with have said something along the lines of, “You know, really, to ‘get’ statistics, you have to start with probability theory.” One published illustration of this stance can be found in 



















































































































































































 The Measure Slack was created and is spearheaded by
The Measure Slack was created and is spearheaded by 



















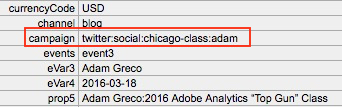
 I’d love to say that the development of this app (if you’re impatient to get to the goodies, you can check it out
I’d love to say that the development of this app (if you’re impatient to get to the goodies, you can check it out 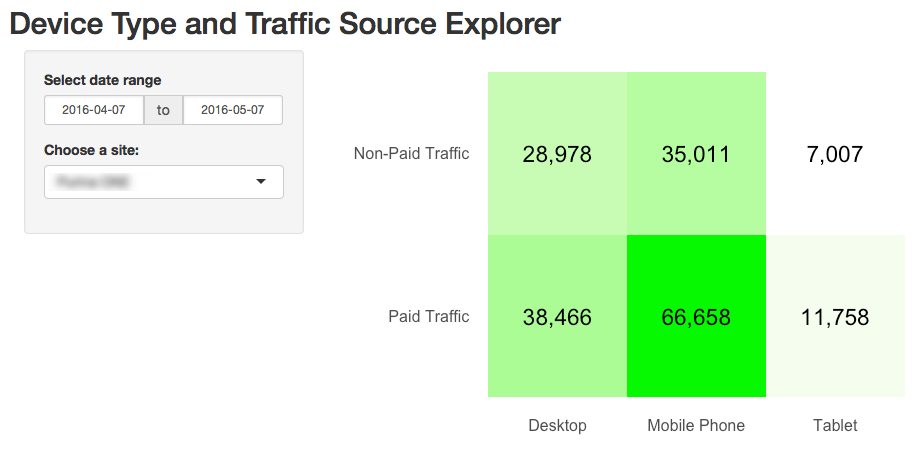







 (This post has a lengthy preamble. If you want to dive right in, skip down to
(This post has a lengthy preamble. If you want to dive right in, skip down to 


































































































































{kind=link}
{kind=link}
{kind=link}