Adobe Target Profile Playbook
This blog post provides a very thorough overview of what Adobe Target’s profile is and how it works. Additionally, we’ve included 10 profile scripts that you can start using immediately in your Adobe Target account.
We also want to share a helpful tool that will allow you to see the Adobe Target Profile in action. This Chrome Extension allows Adobe Target users to visualize, edit, and add profile attributes to your Adobe Target ID or your 1st Party Organization’s ID. Here is a video that shows it in action and if you want to read about all the free Adobe Target features in the extension, please check out this blog post.
THE PROFILE
The Adobe Target profile is the most valuable component of the Adobe Target platform. Without this profile, Adobe Target would be a relatively simple A/B testing solution. This profile allows organizations to take their optimization program to levels not normally achievable with typical testing tools. The profile and the profiling capabilities allow organizations to define attributes for visitors for targeting and segmenting purposes. These attributes are independent of any tests and essentially are creating audiences that can be managed automatically.

As a general example, let’s say an organization decided to build an audience of purchasers.
Within the Adobe Target user interface, users can create profile attributes based off of any data that Target gets passed to it. When someone makes a purchase the URL could contain something like “thank-you.html” or something along those lines.
URLs, among other things, are automatically passed to Adobe Target. So within Target, under the Audiences and then Profiles Scripts, a Target user can say “IF URL CONTAINS ‘thank-you’, set the purchaser attribute to TRUE.
Once saved, anytime a visitor sees a URL that contains ‘thank-you’, they will automatically attain the profile attribute of ‘purchaser’ and that value will be ‘true’. This audience will continue to grow automatically on its own as well and if you had a test targeted to purchasers, visitors who purchased would automatically be included in that test.
Audiences like purchasers can be made based off of any event, offline or online when data is communicated to Adobe Target. The Adobe Target profile is immediate in that Adobe’s infrastructure updates and evaluates the profile before returning test content. This allows audiences created to be used IMMEDIATELY on that first impression.
The image below outlines what happens when calls are made from your digital properties to the global edge network of Adobe Target. Here you can see just how important the profile is as it is the first thing that gets called when Adobe receives a network request.

The profile is much more than this simple example of creating an audience. The Adobe Target Profile is:
- The backbone of Adobe Target: all test or activity participation are visitor profile attributes in Adobe Target. In this image below, you can see our Analytics Demystified home page and on the right, the MiaProva Chrome Extension that is highlighting four tests that I am in on this page and a test that my Visitor ID is associated with in another location. Test and test experiences are just attributes of the unique visitor ID.

- Independent of any single activity or test: This profile and all attributes associated with it are not limited to any single or group of tests and can be used interchangeably across any test type in Adobe Target.
- Is an OPEN ID for custom audience creation: The profile and its attributes map directly to the Adobe Target visitor ID and this ID can be shared, coupled, and joined with other systems and IDs. Before there was A4T for example, you could push your Adobe Target Visitor ID to an eVar, create audiences in Analytics and then target a test to the Target ID’s that mapped to the data in Analytics. This ID is automatically set and can easily be shared with other systems internally or externally.
- Empowerment of 1st, 2nd, and 3rd party data: the profile allows audiences to be created and managed in Adobe Target. The audiences are constructed from 1st party data (an organization’s data), a 2nd party (Adobe Analytics/Target, Google Analytics, etc…), or 3rd party data (audience manager, DemandBase, etc..). The profile allows to consolidate data sources and use them interchangeably giving you the ability to test out any strategies without any limitations that data sources typically have.

- Cross-Device test coordination: Adobe Target has a special reserved parameter name called ‘mbox3rdPartyId’ (more on that below) but essentially this is YOUR organization’s visitor ID. If you pass this ID to Adobe Target, any and all profile attributes are then mapped to that ID. This means that is this ID
- Exportable client side dynamically: Profile attributes can be used in offers used in tests or activities and they can be used as Response Tokens (more on Response Tokens later). To the right here is our Chrome Extension and the boxed area “Adobe Target Geo Metadata” are actually profile attributes or profile tokens injected into the Chrome Extension via Target.
Here is what the offer looks like in Target:
<div class=“id_target”>
<h2>Adobe Target Geo Metadata</h2>
<h3>City: ${user.city}<br>
State: ${user.state}<br>
Country: ${user.country}<br>
Zip: ${user.zip}<br>
DMA: ${user.dma}<br>
Latitude: ${profile.geolocation.latitude}<br>
Longitude: ${profile.geolocation.longitude}<br>
ISP Name: ${user.ispName}<br>
Connection Speed: ${user.connectionSpeed}<br>
IP Address: ${user.ipaddress}</h3>
</div><br>
<div class=“id_map”>
<iframe allowfullscreen frameborder=“0” height=“250” src=“https://www.google.com/maps/embed/v1/search?key=AIzaSyAxhzWd0cY7k-l4EYkzzzEjwRIdtsNKaIk&q=${user.city},${user.state},${user.country}‘” style=“border:0” width=“425”></iframe>
</div>
The BOLD text are actually profile attributes that I have in my Adobe Target account.
When you use them in Adobe Target offers they are called tokens and these tokens are dynamically replaced by Target to the values of the profile attributes. You can even see that I am also passing Adobe Target Profile attributes to Google Mapping Service to return the map based on what Adobe considers to be my geolocation.
- How Automated Personalization does its magic: Automated Personalization is one of Adobe’s Activity types that uses propensity scoring and models to decide what content to present to individuals. Without passing any data to Adobe Target, Automated Personalization uses what data is does see, by way of the mbox or Adobe Target tags, to see what content works well with what visitors. To get more value out of Automated Personalization an organization typically passes additional data to Adobe Target for the models to use for content decisions. Any and all data supplied to Sensei or Automated Personalization outside of the data that Adobe Target collects automatically, are profile attributes. Similarly, the data that you see in the Insights and Segments reports of Automated Personalization is profile attributes (image below of example report).

- The mechanism by which organizations can make use of their internal models: Because the Adobe Target profile and its attributes are all mapped to the Adobe Target ID or your organizational ID, that means you can import any offline scoring that your organization may be doing. Several organizations are doing this and seeing the considerable value. The profile makes it easy to have the data just sitting there waiting for the digital consumer to be seen again so as to respond automatically with the desired content related to the model or strategy.
HOW TO CREATE PROFILES
The beautiful part of the Adobe Target Profile is that it is created automatically as soon as digital consumers come in contact with Adobe Target. This is the case no matter how you use Adobe Target (client-side, server-side, SDK, etc…). When we want to leverage the profile’s ability to define audiences, we are not creating profiles as much as we are creating profile attributes that are mapped or associated with a Profile which is directly mapped to Adobe Target’s ID or your organization’s ID.
There are three main ways to create profile attributes. No matter the method of creating the profile attributes, they all function exactly the same way within Adobe Target. The three ways that Adobe Target users can create mboxes is by way of the mbox (passing the parameter value data as profile parameters), within the Adobe Target user interface, and programmatically via an API.

Client-Side
This is going to be the most popular and easiest way to get profile attributes into your Adobe Target account. For those of you that have sound data layers or have rich data in your tag management system, you are going to love this approach. When Adobe Target is implemented, you can configure data to be passed to the call that is made to Adobe when a visitor consumes your content. This data can be from your data layer, cookies, your tag management, or third-party services that are called.
The image below is from the MiaProva Chrome Extension and highlights the data being passed to Adobe when Adobe Target is called. The call that is made by Adobe Target to Adobe is often referred to as a mbox call (mbox being short for marketing box). The data being passed along are called mbox parameters.
If you look at #3 below in the image, that is a mbox parameter but because it starts with a “profile.” syntax, that makes it a profile attribute that is then immediately associated with the ID’s at #1 (your organizational ID) and #2, Adobe Target’s visitor ID.

The important thing to note is that you are limited to 50 profile attribute per mbox or call to Adobe Target.
Server-side – within your Adobe Target account
The client-side approach will likely be your go-to method especially if you have investments in data layers and tag management. That said, there is another great way to create these profile attributes right within your Adobe Target account.
This method is quite popular because it requires no change to your Adobe Target implementation and anyone with Approver rights in your Target account can create them. I especially appreciate that it allows for processing, similar to Adobe I/O Runtime, to be done server side.
This method can be intimidating though because it requires some scripting experience to really take advantage of all the benefits of this approach. Essentially, you are creating logic based off of what data Adobe Target is getting coupled with the values of any other profile attributes.
Here is a good example, let’s say we want to an audience of current customers and we know that only customers see a URL that contains “myaccount.html”. When Adobe Target makes its call to Adobe, it passes along the URL to Adobe. Here in this server-side approach, we want to say “if URL contains myaccount.html” create an audience or profile attribute of customer equal to true.
Here is what that would look like in Target:

And the script used:
if (page.url.indexOf(‘myaccount.html’) > -1) { return ‘true’; }
Developers and people comfortable with scripting love this approach but for those not familiar with scripting, you can see how it can be intimidating.
After scripts like this are saved, they live in the “Visitor Profile Repository” and are a key component of the “Profile Processing” as seen in the image below. Your Adobe Target account will process any and all of these scripts and update their values if warranted. This all happens before test content is returned so that you can use that profile and its values immediately on the first impression.

To access this server-side configuration of Adobe Target profile attributes, simply click on Audiences in the top-navigation and then on Profile Scripts in the left navigation.

10 Profile Templates: The table below outlines 10 great profile scripts that you can use immediately in your Adobe Target account. Once these scripts are saved, the audiences they create will immediately start to grow. These scripts are a great starting point and help you realize all the potential with this approach.
| DETAILS |
PROFILE ATTRIBUTE NAME |
SCRIPT |
| This profile attribute retains the current visit number of the visitor. |
visitnumber |
if(user.sessionId!=user.getLocal(‘lastSessionId’)) { user.setLocal(‘lastSessionId’, user.sessionId);
return (user.get(‘visitnumber’) | 0) + 1;
} |
| This profile attribute will associate the IP address with the visitor thus enabling you to target activities to certain IP addresses |
ip_address |
user.header(‘x-cluster-client-ip’); |
| This attribute increases with each purchase as defined by impressions of the ‘orderConfirmPage’ mbox which typically exists on thank you pages. |
purchasefrequency |
if (mbox.name == ‘orderConfirmPage’) {
return (user.get(‘purchasefrequency’) | 0) + 1;
} |
| One of my favorites as it allows you to QA tests without having to repeat entry conditions of the tests. Simply use the letters “qa” as part of your query string and this profile is set to true! Very popular attribute. |
qa |
if (page.param(“qa”)) {
return “true”;
} |
| Day of the week. Helpful such that it highlights the incorporation of standard javascript functions. |
day_of_visit |
if (mbox.name == “target-global-mbox”) {
var today = new Date().getDay();
var days = [‘sunday’, ‘monday’, ‘tuesday’, ‘wednesday’, ‘thursday’, ‘friday’, ‘saturday’];
return(days[today]);
} |
| This attribute sums up the total revenue per visitor as they make multiple purchases over time. |
amountSpent |
if (mbox.name == ‘orderConfirmPage’) {
return (user.get(‘amountSpent’) || 0) + parseInt(mbox.param(‘orderTotal’));
} |
| This attribute sums up the number of items purchased by a visitor over time. |
purchaseunits |
if (mbox.name == (‘orderConfirmPage’)) {
var unitsPurchased;
if(mbox.param(‘productPurchasedId’).length === 0){
unitsPurchased = 0;} else {
unitsPurchased = mbox.param(‘productPurchasedId’).split(‘,’).length;
}
return unitsPurchased;
} else {
return ‘0’;
} |
| This attribute simply sets a value of true based off of the URL of the page. You can easily modify this script for any page that is important to you. |
myaccount |
if (page.url.indexOf(‘myaccount’) > -1)
{
return ‘true’;
} |
| This attribute is a good example of using an mbox name and an mbox parameter to set an attribute. I used this one for Marketo when a user submits a form. This creates a ‘known’ audience segment. |
form_complete |
if ((!user.get(‘marketo_mbox’)) && (mbox.param(‘form’) == (‘completed’))) {
return ‘true’;
} |
| This script enables mutual exclusivity in your Adobe Target account. This attribute creates 20 mutually exclusive swim lanes. Visitors are randomly assigned a group number 1 through 20. |
random_20_group |
if (!user.get(‘random_20_group’)) {
var ran_number = Math.floor(Math.random() * 99),
query = (page.query || ”).toLowerCase();query = query.indexOf(‘testgroup=’) > -1 ? query.substring(query.indexOf(‘testgroup=’) + 10) : ”;
if (ran_number <= 4) {
return ‘group1’;
} else if (ran_number <= 9) {
return ‘group2’;
} else if (ran_number <= 14) {
return ‘group3’;
} else if (ran_number <= 19) {
return ‘group4’;
} else if (ran_number <= 24) {
return ‘group5’;
} else if (ran_number <= 29) {
return ‘group6’;
} else if (ran_number <= 34) {
return ‘group7’;
} else if (ran_number <= 39) {
return ‘group8’;
} else if (ran_number <= 44) {
return ‘group9’;
} else if (ran_number <= 49) {
return ‘group10’;
} else if (ran_number <= 54) {
return ‘group11’;
} else if (ran_number <= 59) {
return ‘group12’;
} else if (ran_number <= 64) {
return ‘group13’;
} else if (ran_number <= 69) {
return ‘group14’;
} else if (ran_number <= 74) {
return ‘group15’;
} else if (ran_number <= 79) {
return ‘group16’;
} else if (ran_number <= 84) {
return ‘group17’;
} else if (ran_number <= 89) {
return ‘group18’;
} else if (ran_number <= 94) {
return ‘group19’;
} else {
return ‘group20’;
}
} |
API
The third approach that we highlight is by way of API. Many organizations leverage this approach because the data that they want to be profile attributes is not available online and so passing it client side is not an option. Similarly, we can’t use server-side scripting either because of data communications. Many financial institutions and organizations that have conversion events offline typically use this approach.
Essentially, how this works is you leverage Adobe’s API to push data (profile attributes) to Adobe based on your visitor ID (mbox3rdPartyId) or by Adobe Target’s ID. The documentation on this approach can be found here: http://developers.adobetarget.com/api/#updating-profiles
mbox3rdPartyId or thirdPartyId
This is one of the easiest things you can do with your Adobe Target account and yet it is one of the most impactful things you can do to your optimization program.

The mbox3rdPartyId is a special parameter name that is used when you pass YOUR visitor ID to Adobe Target.
The image to the right is the MiaProva Chrome Extension which is showing the data that is communicated to Adobe Target. The highlighted value is this mbox3rdPartyId in action.
Here I am mirroring my ID, with the Adobe ID. This will allow me to coordinate tests across devices such that if a visitor is getting Experience B on one device, they will continue to get Experience B on any other device that has this ID.
Any and all data that is available offline by this ID can be imported to Adobe Target via API! This further enables offline modeling and having targeting in place even before the digital consumer arrives on your digital properties.
If your digital property has a visitor ID that they manage, you most definitely want to integrate this into Adobe Target.
Response Tokens
To allow organizations to easily made profile attributes and their values available to other systems, Adobe Target has Response Tokens. Within your Adobe Target account under “Setup” and then “Response Tokens” as seen in the image below, we can toggle on or off Response Tokens, which are Profile Attributes.

When you turn the toggle to on, Adobe Target will push these profile attribute values back to the page or location where the Adobe Target call came from.
This feature is how Adobe Target can integrate with third-party Analytics tools such as Google Analytics. It is also how the MiaProva Chrome Extension works because as part of that setup, we instruct turning the above-toggled attributes to on.
The immediate image below is what the Adobe Target response looks like where I have a test running. The first component (in green) is the offer that is changing the visitor’s experience as part of the test. The second component (in blue) are response tokens that have been turned on. Pretty cool way to easily get your profile attributes part of your data layer or for the consumption of other tools such as ClickTale, internal data lakes, Heap, MiaProva, etc…

Expiration
A very important thing to note. By default, the Adobe Target Profile lasts for 14 days of inactivity. You can submit a ticket to client care to extend this lifetime. They can extend it for 12 to 18 weeks. This period of time is a rolling period based off of inactivity. So if a visitor arrives on day 1 and then on day 85, the visitor ID and its attributes will be gone if your profile expiration was at 12 weeks (84 days).
If the visitor was seen at any point before the profile expiration, Adobe Target will push its expiration back by the profile expiration period.














































































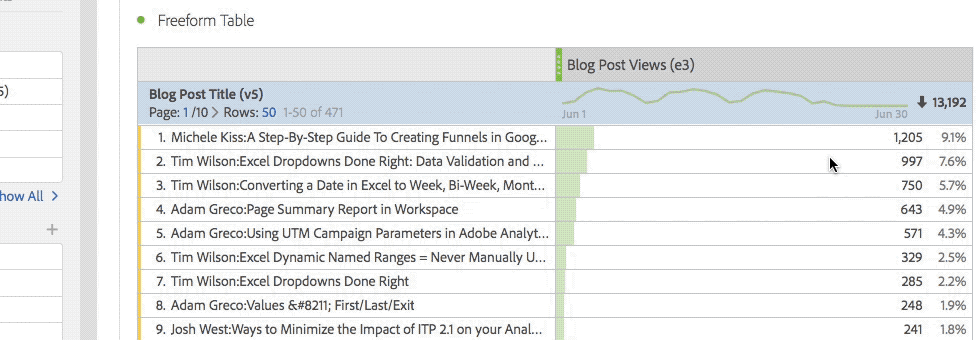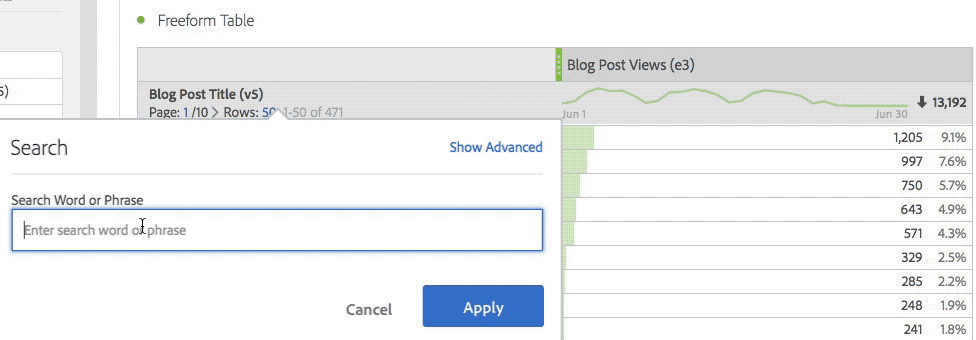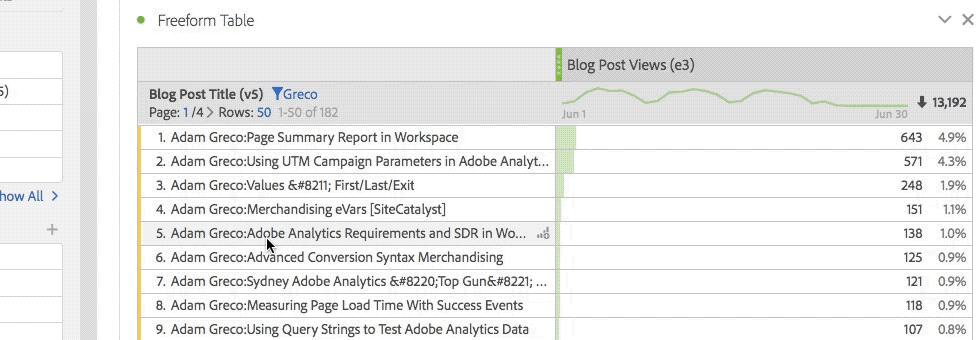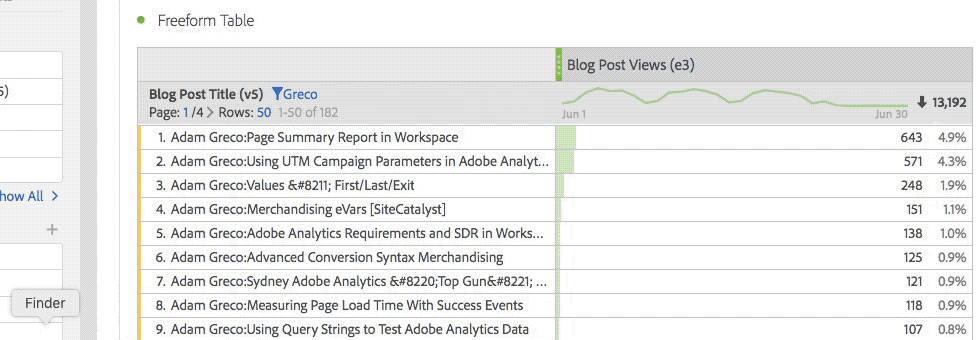
 As I mentioned, some of the greatest stuff in Analysis Workspace is hidden or not super obvious to users. In Freeform tables, right-clicking opens up many great options that casual users don’t know about. While the 1980’s gamer in me loves the easter egg aspect of Workspace, especially when I can show someone a new feature they didn’t know about, I can tell you after training new folks on the product, they did not think it was as cool as I did! So the first part of this post will cover all of the “hidden” stuff that frustrated my students.
As I mentioned, some of the greatest stuff in Analysis Workspace is hidden or not super obvious to users. In Freeform tables, right-clicking opens up many great options that casual users don’t know about. While the 1980’s gamer in me loves the easter egg aspect of Workspace, especially when I can show someone a new feature they didn’t know about, I can tell you after training new folks on the product, they did not think it was as cool as I did! So the first part of this post will cover all of the “hidden” stuff that frustrated my students.