As someone who has made a living auditing, fixing and improving Adobe Analytics implementations, there are a few questions related to this that I receive all of the time. One of these questions, is whether a company doing a cleanup/re-implementation of their Adobe Analytics implementation should make changes to their existing report suite(s) or start over with brand new report suites. As you would expect, there is no one right answer to this, but I thought I would share some of the things I consider when making this decision.
Auditing What You Have
The first step of the cleanup process for an Adobe Analytics implementation is doing a thorough audit or review of what you have today. I can’t tell you how many companies I have worked with who hired me to do a “quick” review of their implementation and had no idea how inaccurate or bad it really was in its current state. Too often, I see companies that don’t question the data they are collecting and assume it is useful and that the data is correct. Trust me when I tell you that, more often than not, it isn’t! I’d say that most of the companies I start with have scores around 60% – 70% out of 100% when it comes to their Success Events, eVars and sProps functioning properly. If you are unsure, I suggest you read this white paper that I wrote in partnership with Adobe (and if you think you may have some issues or want an objective validation that your implementation is in good shape, check out this page which describes my service in this area).
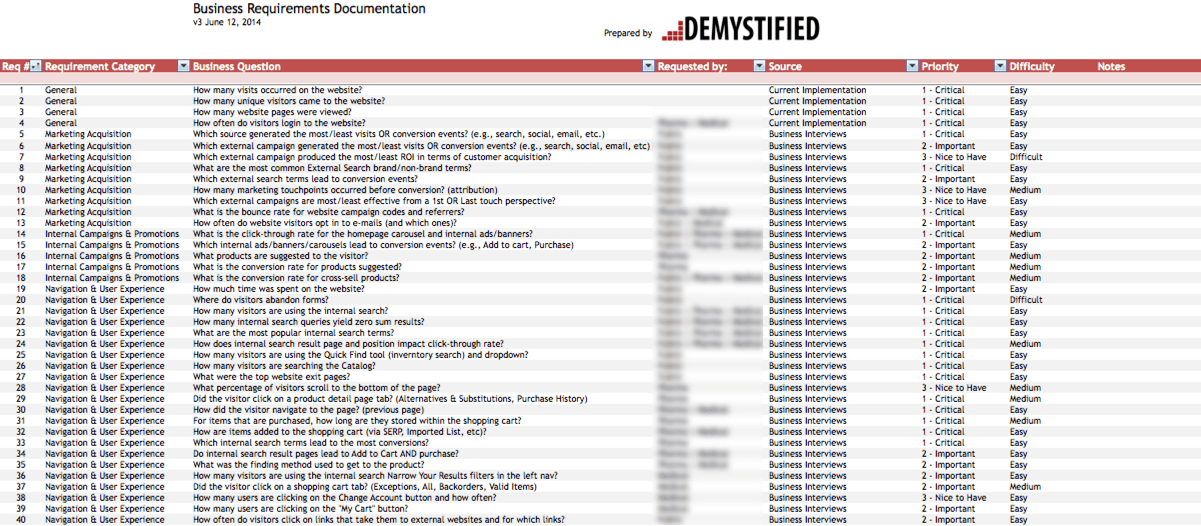
As you audit your existing implementation, you will want to make sure to look at the following:
- How many report suites do you have and which are actively being used (and which can be hidden in the Admin Console)? How consistent are these report suites? If you select all of them in the Admin Console, how often do you see “Multiple” values? The more you do, the more you may be in trouble.
- How good is your data? If you have incomplete or inaccurate data, what is the value of sticking with your old report suites that are filled wth garbage?
- How important to your business is year over year data? Some organizations live and die by YoY data, while others focus more on recent periods, especially if they have recently undergone a website re-design.
The answers so these types of questions will have impacts on the ultimate decision as I will dive into below.
Old Report Suites or New Ones?
So getting back to the original question – if you are going to re-implement, should you use existing report suites or new ones? The only way I can explain this is to show you the scenarios that I see most often.
Report Suite Inconsistency
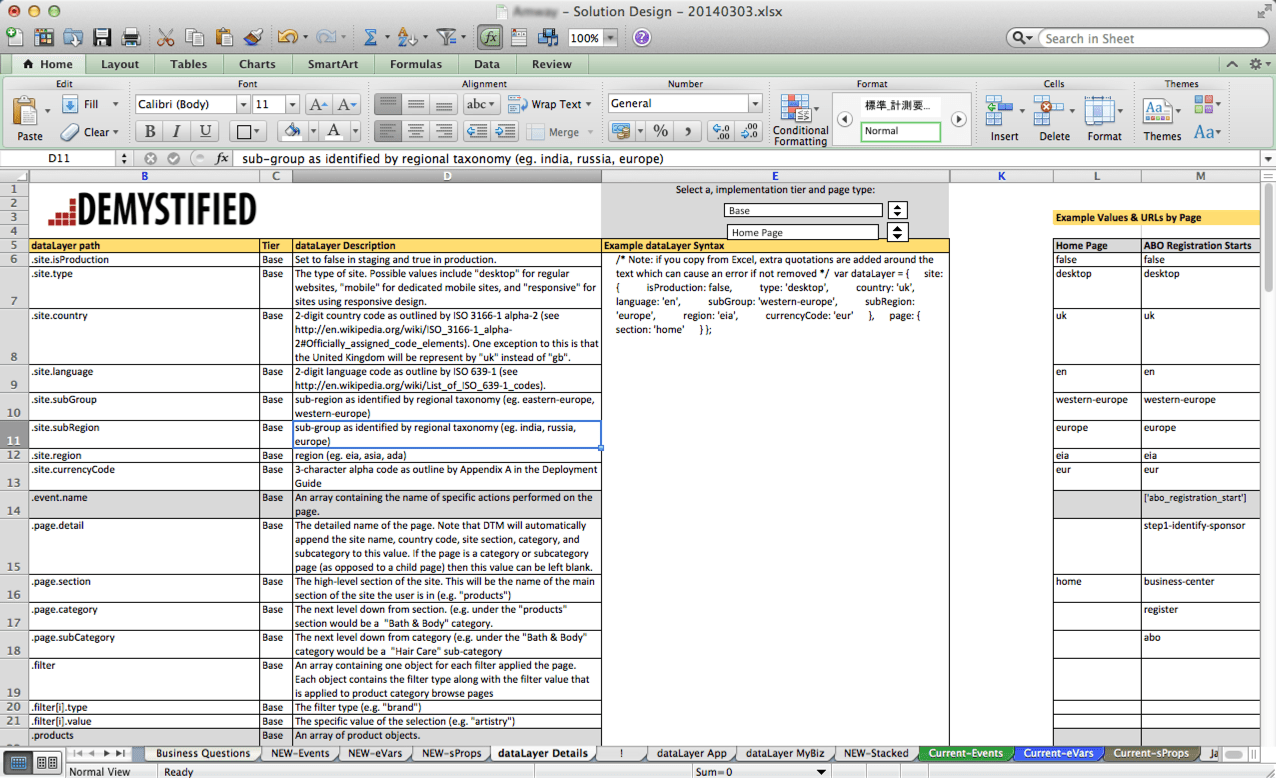
If in the audit process above, you find that you have lots of report suites, and that the variable assignments in each of them are pretty different, the odds are that you should start from scratch with new report suites and, this time, make sure that they are set-up consistently. As mentioned above, the easiest way to see this is to select all of your active suites, choose a variable type (i.e. Events, eVars or sProps) and view the settings like this:

If you see this when selecting multiple report suites, the odds are you are in trouble, unless you manage lots of different websites that have absolutely nothing in common across them. I tend to see this issue most in the following situations:
- Different sites are implemented by different parts of the business and no communication exists between them or there is no centralized analytics “Center of Excellence”
- One business is acquired and both used the same analytics tool, but the implementations were done while the companies were separate
- Two businesses or business units with different websites/products had implemented separately and, only later, decide they want to combine their data
- A mobile team goes rogue and creates new report suites and tags all mobile sites/apps with a brand new set of variables without talking to the desktop group
Regardless of how you got there, the reason report suite inconsistency is so bad, is that salvaging it requires a massive variable reconciliation if you want to use your existing report suites and, even then, all but one suite is going to have different data in it than it did in the past. For example, let’s say that event 1 above is “Internal Searches” for two report suites and for the eight other suites has a different definition. That means you have nine different definitions for event 1 across ten report suites. Even if you lay down the law and say that after your re-implementation, event 1 will always be “Internal Searches,” you will still have numbers that are not Internal Searches in eight out of 10 of your report suites historically. Thus, if someone looks at one of the suites that historically didn’t have event 1 as Internal Searches, for a long period of time, it will not actually be Internal Search data. Personally, I’d rather have no historical data than potentially misleading data. In addition, I think it is easier to start anew and tell the developers from all of your disparate sites that they must move their data from wherever they have it now to the new standard variable assignment list, rather than trying to map existing data to new variables using Processing Rules, DTM, VISTA Rules or other work-arounds. Doing the latter just creates Band-Aids that will eventually break and corrupt your data once again in the future.
Here is an example of the eVars for one of my clients:

In this case, I only compared five different report suites out of more than fifty that they have in total. As you can see, reconciling this to ultimately have a global report suite or to send all data into one suite would be quite a challenge!
Conversely, if it turns out that all of your suites have pretty good variable definition consistency, then you can move the data from the incorrect variable slots to the correct ones in your lower priority report suites and continue using your existing report suites. For example, if you have one main report suite and then a bunch of other less significant report suites (like micro-sites), you may decide that you want to keep the main suite the way it is and force all of the other suites to change and adhere to the variable definitions of the main suite. This is a totally acceptable solution and will allow you to have year over year data for your main suite at least.
However, if you go down this path, I would suggest that if there are variables that the non-main report suite uses, that they be added to the main report suite in new variable slots so that eventually all of your report suites are consistent. For example, let’s say that one of the lesser important suites has a success event #1 that is registrations, but there is no registrations event in the main suite that you want to persist. In this case, you should move event 1 in the non-main suite to the next available event number (say event 51) and then add this event 51 to the main report suite as well. If you will never have registrations in your main suite, it is still ok to label event 51 as registrations, simply disable it in the admin console. This way, you avoid any variable definition conflicts in the future. For example, if the main report suite needs a new success event they would use event 52 instead of event 51 since they now know that event 51 is taken elsewhere. The only time this gets tricky is when it comes to eVars, since they are limited to 100 for most customers, but conserving eVars is a topic for another day!
Regardless of what you find, looking at the consistency of your variable definitions is an important first step in the process.
Data Quality
As mentioned above, if the data quality for your existing implementation isn’t very good, then there are fewer reasons to not start fresh. Therefore, another step I take in the process is to determine what percent of my Success Events, eVars and sProps in my current implementation I trust. As described in this old post, data quality is paramount when it comes to digital analytics and if you aren’t willing to put your name on the line for your data, then it might as well be wrong. Even if your report suites are pretty consistent (per the previous section), there may be benefits to starting over with new report suites if you feel that the data you have is wrong or could be misleading.
When I joined Salesforce.com many years ago to manage their Omniture implementation, I had very little faith in the data that existed at the time. When doing my QA checks, it seemed like most metrics came with a list of asterisks associated with them, such that presentation slides looked like bibliographies! While I hated the idea of starting over, I decided to do it because it was the lesser of two evils. It caused some temporary pain, but in the end, helped us shed a lot of baggage and move forward in a positive direction (you can read a lot more about how we did this in this white paper). For this reason, I suggest you make data quality one of your deciding factors in the new vs. old report suite decision.
Year over Year Data
Finally, there is the issue of year over year data. As mentioned above, if your variable definitions are completely inconsistent and/or your data quality is terrible, you may not have many options other than starting with new suites for some or all of your report suites. Moreover, if your data quality is poor, having year over year flawed data isn’t much of an improvement over having no year over year data in my opinion. The only real data that you would lose if your data quality is bad is Page Views, Visits and Unique Visitors (which are pretty hard to mess up!). In most cases, I try to avoid having year over year data be the driving force in this decision. It is a factor, but I feel that the previous two items are much more important.
Sometimes, I advise my clients to use Adobe ReportBuilder as a workaround to year over year data issues. If you decide to move to new report suites, you can build an Excel report using ReportBuilder that combines two separate data blocks into one large Excel data table that can be graphed continuously. In this case, one data block contains data for a variable in the old report suite and the other data block contains data for the same data point in a different variable slot in the new report suite. But to an end user of the Excel sheet, all they see is one large table that updates when they refresh the spreadsheet.
For example, let’s imagine that you have two report suites and one has internal searches in event 1 and the other has internal searches in event 5. Then you decide to create a brand new suite that puts all internal searches into event 1 as of January 1st. In ReportBuilder (Excel), you can create one data block that has event 1 data for suite #1 for dates prior to January 1st, another data block that has event 5 data for suite #2 for dates prior to January 1st and a third data block that has event 1 data for January 1st and beyond in the new report suite. Then you simply use a formula to add the data from event1 and event 5 in the data blocks that precede January 1st and then put that data block directly next to the final data block that contains event 1 data starting January first (in the new suite). The result will be a multi-year view of internal search data that spans all three report suites. A year later, your new report suite will have its own year over year data in the new combined event 1, so eventually, you can abandon the Excel workaround and just use normal Adobe Analytics reporting to see year over year data.
While this approach may take some work, it is a reasonable workaround for the few major data points that you need to report on year over year while you are making this transition to a newer, cleaner Adobe Analytics implementation.
Justification
Sometimes, telling your boss or co-workers that that you need to re-implement or start over with new report suites can be a difficult thing to do. In many respects, it is like admitting failure. However, if you do your homework as described above, you should have few issues justifying what you are doing as a good long-term strategy. My advice is to document your findings above and share them with those who may complain about the initiative. There will always be people who complain, but at the end of the day, you need to instill faith in your analytics data and if this is a necessary step, I suggest you do it. I heave learned over the years that the perception of your organization’s analytics team is one of the most critical things and something you should safeguard as much as you can. In our line of work, you are asking people to make changes to websites and mobile apps, partly based upon the data you are providing. That demands a high level of trust and once that trust is broken it is difficult to repair.
I also find that many folks I work with were not around when the existing implementation was done. This is mainly due to the high turnover rate in our industry, which, in turn, is due to the high demand for our skills. If you are new to the analytics implementation that you now manage, I recommend that you perform an audit to make sure what you inherited is in good shape. As described in books like this, you have a narrow window of time that is ideal for cleaning things up and asking for money if needed. But if you wait too long, the current implementation soon becomes “your problem” and then it is harder to ask for money to do a thorough review or make wholesale changes. Plus, when you first start, you can say things like “You guys were the ones who screwed this up, so don’t complain to me if we have to start it over and lose YoY data…You should have thought of that before you implemented it incorrectly or with shoddy data quality!” (You can choose to make that sound less antagonistic if you’d like!)
Avoiding a Repeat in the Future
One last point related to this topic. If you are lucky enough to be able to clean things up, reconfigure your report suites and improve your data quality, please make sure that you don’t ever have to do that again! As you will see, it is a lot of work. Therefore, afterwards, you want to put processes in place to ensure you don’t have to do it again in a few years! To do this, I suggest that you reduce the number of Adobe Analytics Administrators to only 1-2 people, even if you are part of a large organization. Adding new variables to your implementation should be a somewhat rare occurrence and by limiting administration access to a select few, you can be sure that all new variables are added to the correct variable slots. I recommend doing this through a digital analytics “center of excellence,” the setup of which is another one of the services that I provide for my clients. As they say, “an ounce of prevention is worth a pound of cure!”